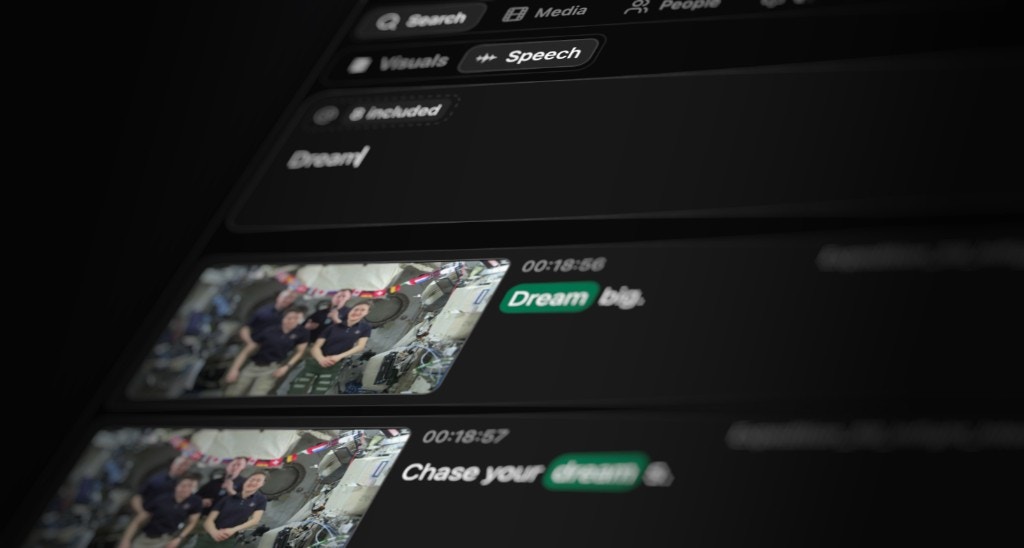
Overview
Speech search allows you to find any word or phrase that has been spoken in your footage. Unlike visual search, which understands what things look like, speech search works with the actual words and dialogue in your media files. Speech search relies on machine learning models that transcribe spoken language into searchable text. Once your media is analyzed, you can search for any word or phrase that was spoken, and Jumper will find and rank every exact or fuzzy match.How transcription works
During the analysis phase, Jumper’s speech models process the audio of your media files and convert spoken words into text transcriptions. This happens automatically when you analyze media for speech. The transcription process:- Converts speech to text with timestamps
- Stores the transcription data for searching
- Handles different accents, background noise, and varying audio quality
Audio channels
You can transcribe one or more selected audio channels. Set which channels to transcribe per file in the Media tab. This is useful when dialogue is split across channels, such as a separate lavalier per speaker. When several channels contain the same dialogue, Jumper merges the transcripts and removes the duplicate speech, so a phrase picked up by two mics doesn’t show up twice in your results.Speaker detection
Speaker detection identifies who is speaking in a transcript. It’s on by default. Jumper detects speakers automatically, lets you name them, and lets you filter speech search to a specific speaker. If you already know how many people are in a recording, you can set the expected number of speakers before analysis (auto, 1–4, or 5+) to improve detection. There’s no guarantee the model labels every speaker correctly, especially with overlapping speech or very short utterances. Review and rename speakers where needed.How search works
When you perform a speech search, Jumper searches through the transcriptions of your analyzed media files. The search finds and ranks every exact or fuzzy match of the word or phrase you type in. Exact matches: When you search for a specific word or phrase, Jumper finds all instances where that exact text appears in the transcriptions. Fuzzy matches: The search also handles variations and similar-sounding words, so you can find what you’re looking for even if the exact spelling or phrasing differs slightly. Results are ranked by relevance, showing you the most likely matches first. Each result includes timestamps so you can see exactly when the words were spoken in your footage.Language support
Jumper supports over 100 languages for speech transcription. The speech models can automatically detect the language being spoken, or you can specify the language during analysis for improved transcription accuracy. When you know the spoken language in a particular file, specifying it explicitly helps the model focus on that language’s characteristics, resulting in more accurate transcriptions. The default setting is auto-detection, which works well for most cases but may benefit from manual language selection when dealing with mixed-language content or specific dialects. For a complete list of supported languages, see Supported Languages.Transcription files
Along with making your footage searchable, Jumper also generates plain text transcription files when you analyze media for speech. These files contain the complete transcriptions of what was said in your media. To work with the transcript inside Jumper (jump to lines, hide segments, export), use the Script Editor. The transcription files are stored alongside your analysis data and can be accessed by right-clicking on a media file in the Media table.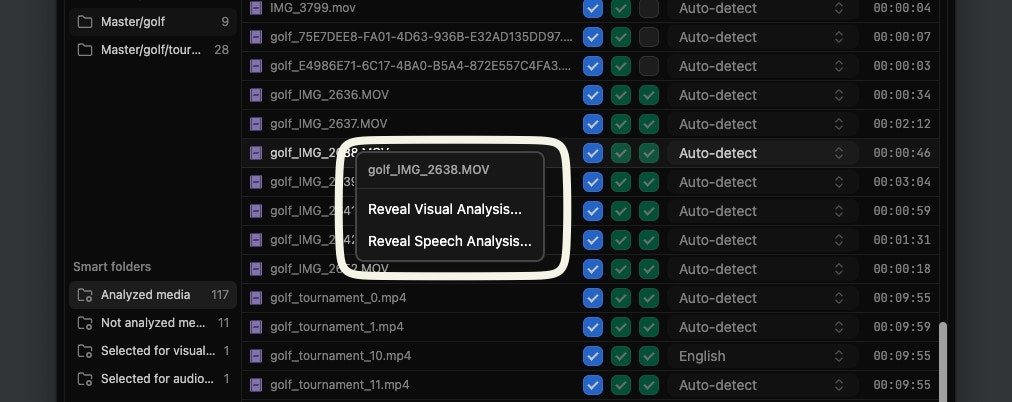
Reveal Speech Analysis... you will find two plain text files with the actual transcriptions.
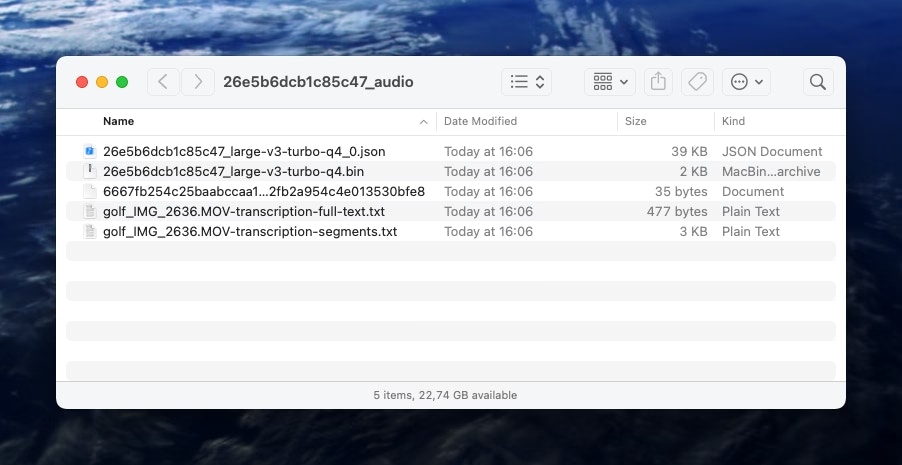
transcription-full-text.txtcontains the entire transcripttranscription-segments.txtcontains the entire transcript but segmented with time codes
- Review or edit the transcriptions outside of Jumper
- Share transcriptions with others
- Use the transcriptions in other applications
- Verify what was transcribed
Frequently Asked Questions
Can Jumper distinguish who said what (speaker diarization)?
Can Jumper distinguish who said what (speaker diarization)?
Yes. Speaker detection identifies who is speaking, lets you name speakers, and lets you filter speech search to a specific speaker. See Speaker detection above.
Can Jumper transcribe more than one audio channel?
Can Jumper transcribe more than one audio channel?
Yes. You can select one or more audio channels to transcribe. When the same dialogue appears on multiple channels, Jumper merges the transcripts and removes the duplicate speech. See Audio channels above.